


![]()
«Moving Object
Detection Method ‘LOTS’» Paizakis P.
«Ανίχνευση κινούμενων αντικειμένων με την μέθοδο ‘LOTS’» Παϊζάκης Π.
![]()
Abstract
Identifying moving objects is
a critical task for many computer vision applications. It provides a
classification of the pixel into either foreground or background. An algorithm
is presented for segmentation of moving objects in image sequences. For each
frame in the video sequence, an initial segmentation is performed. The result
of this segmentation is a set of regions that completely cover the image. Then,
each region is examined and classified either as moving object or as
background. Thus, the problem of moving objects segmentation is transformed
into a region classification. Each region in the initial partition must be
either a part of moving object or part of the background. This classification
rely on temporal information or on intensities differences between successive
frames or rely on motion. A common approach used to achieve such classification
is background removal. An approach for moving object detection have been
implemented is LOTS (Lehigh Omnidirectional Tracking System) algorithm, a
region-based algorithm.
Keywords: Surveillance Systems, Object detection,
Segmentation, Object Tracking
![]()
Περίληψη
Η αναγνώριση κινούμενων αντικειμένων αποτελεί ένα σημαντικό κομμάτι για πολλές εφαρμογές μηχανικής όρασης. Παρέχει μία ταξινόμηση των ιχνοστοιχείων σε ιχνοστοιχεία υποβάθρου και σε ιχνοστοιχεία κινούμενων αντικειμένων. Ένας αλγόριθμος για διαχωρισμό των κινούμενων αντικειμένων από το υπόβαθρο παρουσιάζεται. Για κάθε εικόνα του βίντεο, κάθε περιοχή της εικόνας εξετάζεται και ταξινομείται ως κινούμενο αντικείμενο ή ως υπόβαθρο. Αυτή η ταξινόμηση βασίζεται σε χρονική πληροφορία ή σε διαφορές έντασης μεταξύ συνεχόμενων εικόνων ή βασίζεται στην κίνηση. Μία διαδεδομένη προσέγγιση για την επίτευξη τέτοιας ταξινόμησης είναι η αφαίρεση του υποβάθρου. Η μέθοδος ανίχνευσης κινούμενων αντικειμένων που έχει υλοποιηθεί βασίζεται στην χωρική πληροφορία.
![]()
1. Introduction
Understanding the motion of
objects moving in a scene by the use of video is both a challenging scientific problem
and a very fertile domain with many promising applications. Thus, it draws
attention of several researches, and commercial companies. Our motivation is
the study and the implementation of moving object detection methods.
Moving Object
detection is the basic step for further analysis of video. It handles
segmentation of moving object from stationary background objects. This not only
creates a focus of attention for higher level processing but also decreases
computation time considerably. Commonly used techniques for object detection
are background subtraction and also statistical models. Due to environmental
conditions such as illumination changes, shadows and waving tree branches in
the wind object segmentation is a difficult and significant problem that needs
to be handled well for a robust visual surveillance system. An algorithm for
object detection with background subtraction (LOTS) is presented in this paper.
The next step in the video analysis is tracking, which
can be simply defined as the creation of temporal correspondence among detected
objects from frame to frame. This procedure provides temporal identification of
the segmented regions and generates cohesive information about the objects in
the monitored area such as trajectory, speed and direction. The output produced
by tracking step is generally used for higher level activity analysis.

figure 1 A binary background/foreground image.
![]()
2. Related Work on real time object
detection
Background subtraction is particularly
a commonly used technique for motion segmentation in static scenes. It attempts
to detect moving regions by subtracting the current image pixel-by-pixel from a
reference background image that is created by averaging images over time. The
pixels where the difference is above a threshold are classified as foreground. The reference background is
updated with new images over time to adapt to dynamic scene changes.
Heikkila and Silven [13] a pixel at
location (x, y) in the current image It is marked as foreground if
![]()
is satisfied where ![]() is a predefined threshold. The
background image BT is updated as follows
is a predefined threshold. The
background image BT is updated as follows
![]()
Toyama et al. [14] propose a three component
system for background maintenance, (Wallflower algorithm): the pixel-level component which performs
Wiener filtering, the region-level component,
fills in homogenous regions of foreground objects and the frame-level component for sudden, global changes. Two
auto-regressive background models are used, along with a background threshold.
Halevi
and Weinshall [15] present an approach to the tracking of very non rigid
patterns of motion, such as water flowing down a stream. The algorithm based on
a “disturbance map”, which is obtained by linearly subtracting the temporal
average of the previous frames from the new frame. Every local motion creates a
disturbance having the form of a wave, with a “head” at the present position of
the motion and a historical “tail” that indicates the previous locations of
that motion. The algorithm is very fast and can be performed in real-time.
Wren
et al. [10], Pfinder models the background using a single Gaussian
distribution and uses a multi-class statistical model for the tracked object; uses a simple scheme, where background pixels
are modelled by a single value and foreground pixels are modeled by a mean and
covariance, which are updated recursively.
Haritaoglu et al. [4] propose a real time
visual surveillance system, W4, for detecting and tracking multiple
people and monitoring their activities in an outdoor environment. The system
can identify and segment the objects that are carried by people and can track
both objects and people separately. The W4 system uses a statistical background model where
each pixel is represented with its minimum (M) and maximum (N) intensity values
and maximum intensity difference (D) between any consecutive frames observed
during initial training period where the scene contains no moving objects. A
pixel in the current frame It is classified as foreground if it
satisfies:
![]() or
or ![]()
The statistics of the
background pixels that belong to the non-moving regions of current frame are
updated with new image data.
![]()
3. Moving Object Detection
This chapter introduces the
concept of adaptive background models for video sequences and describes methods
for background modelling using background subtraction and statistical
approaches. Focus is given on understanding the underlying theory of the
method. The algorithm LOTS, is a moving object detection and tracking algorithm
that based on background subtraction.
In computer vision
a background model refers to an estimated image or the statistics of the
background of a scene which an image or video sequence depicts. In object
tracking from video sequences, i.e. tracking people, cars, etc., the background
model plays a crucial role in separating the foreground from the background.
The simplest form of
background model is perhaps taking an image of the scene when no objects are
present and then using that image as the background model. The foreground can
be determined by frame differencing, i.e. comparing each pixel in the currently
sampled frame to the background image and if the difference is below some
threshold, the pixel is classified as background. Such a solution may be
sufficient in a controlled environment, but in an arbitrary environment such as
outdoor scenes, light conditions will vary over time. Also, it may be either
difficult or impossible to be able to take an image of the scene without any
objects present. It is therefore highly desirable to have a background model
that adapts to the scene regardless of its initial state.
This paper focuses
on adaptive background models that can be maintained in real-time. In some
literature the adaptive methods explained here are referred to as recursive
techniques, since the current background model is recursively updated in each
iteration.
![]()
4.
LOTS algorithm
This algorithm operates on
grey scale images. It uses two background images and two per-pixel thresholds ([5],[7]).
The two backgrounds model periodic changes. The per-pixel threshold image can
treat each pixel differently, allowing the detector to be robust to localized
noise in low-size image regions. The per-pixel threshold evolves according to a
pixel label provided by a Quasi Connected Components analysis (QCC).
The
steps of the algorithm are:
I.
Background
Modeling
We presume a two background
model, the primary background ![]() and the secondary
background
and the secondary
background![]() , where
, where ![]() is the pixel index.
The pixel intensity value is
is the pixel index.
The pixel intensity value is![]() . We presume the input at time t-1 was closest to the primary
model
. We presume the input at time t-1 was closest to the primary
model ![]() and if that is not
true we swap the pixels between the two background images. We define the
difference images as
and if that is not
true we swap the pixels between the two background images. We define the
difference images as
![]() (1)
(1)
![]() (2)
(2)
and we define variable ![]() as the index with
smaller difference
as the index with
smaller difference ![]() and
and ![]() as the remaining index. We allow for some process to label
the pixel
as the remaining index. We allow for some process to label
the pixel ![]() as being in the target
set T or in the non-target set N. We update the background as
as being in the target
set T or in the non-target set N. We update the background as
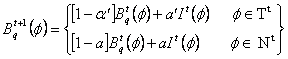 (3)
(3)
where ![]() smaller than
smaller than ![]() . In our algorithm we used as
. In our algorithm we used as ![]() and
and![]() . The other background model is not updated,
. The other background model is not updated,
![]() (4)
(4)
The motivation of equation 3
is to support temporal changes in lighting. Furthermore the blending of a
moving target with the background process produces a ‘beneficial ghost’ of the
target’s path. The use of ![]() <
<![]() allows the system to more slowly adapt in target regions,
limiting how quickly a target will be blended with the background.
allows the system to more slowly adapt in target regions,
limiting how quickly a target will be blended with the background.
Lots does not update
the background images every frame. It is updated every 64 frames and it reduces
the cost. If the background updated each frame, it became the most
computationally expensive component of the system, larger than the operations
of subtraction and thresholding.
II.
Grouping: Quasi-Connected Components (QCC)
After change detection is
applied, most systems form regions by collecting connected pixels. Many systems
augment their connected components with morphological processing.
In this section is presented an approach which combines
grouping with the thresholding into a process called quasi-connected components
(QCC).
A main problem for any pixel-level change detection
technique is the setting of the threshold for deciding what a significant
change is. If one chooses a high threshold, to maintain a small false alarm
then the miss detection rate is increased. On the other hand, the lower
threshold needed for low miss detection rate and a high false alarm rate. In
our algorithm we use thresholding-with-hysteresis
(TWH). The idea is to have two thresholds, a high threshold (Th)
and low threshold (TL). Regions are defined by connected components
pixels above the low threshold where the region also contains a given fraction
of its pixels above the high threshold. TWH fills gaps between high-confidence
regions in a more meaningful way. A problem is that with a low threshold near
zero, gaps will occur because parts of targets can match the background
exactly. A technique that can fill across small gaps is the quasi-connected components that combine
TWH with gap filling and connected component labeling. The process insures that
each pixel in a quasi-connected region is “connected” to a given number of
pixels above the high threshold, even if the pixel is within a gap.
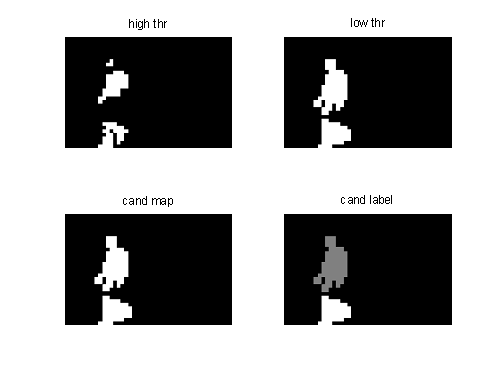
figure 2 Example showing the high threshold image, the low
threshold image, the candidate
map and the
candidate labeling of regions
Figure 2 shows the images that
extracted using Lots algorithm. In the left upon image is illustrated the image
that contains pixels above the high threshold value, the right upon image is created by the pixels
that are above the low threshold. In the bottom left image is illustrated the
blended image from the merge of low threshold and high threshold images. In the
bottom right image we present the candidate labeling of regions that
corresponds to moving objects.

figure
3
Lots Algorithm
The quasi-connected algorithm
gathers information about the number of change pixels above the high threshold in
an image block of the difference image and stores it as an image value in a
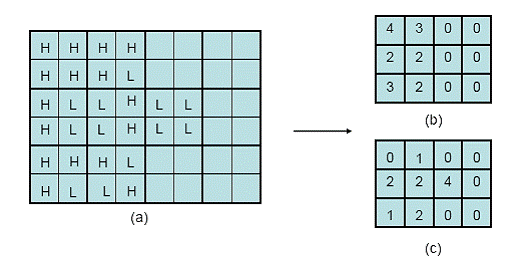
lower resolution image on which connected component analysis is performed. An
example of this is illustrated in Figure 4, where Figure 4a represents the
high/low threshold image where H and L denote the high and low threshold pixels
found in the difference image respectively. In this example, the parent image
represents the downsampling of the original image by a factor of ![]() and Figure 4c
represents
and Figure 4c
represents ![]()
![]()
figure
4
(a) Low-High Threshold Image (b) High Threshold Parent Image
(c) Low Threshold Parent Image
At QCC approach, during the
detection phase, the system builds a lower resolution image of the pixels above
threshold (the 24x24 image is compressed down to the smaller 6x6 image). This
is called the parent image, where each parent pixel has multiple associated
pixels that contribute to it. The value of each pixel in this parent image is a
count of how many of its associated children (high resolution) pixels were
above the low threshold and how many were above the high threshold. The count
for exceeding the low threshold is
in the low order word; the count for exceeding the high threshold is in the
high order word. Since the resolution is reduced by a factor of four in each direction. The low
order and high order words of the parent image contain values between zero and
sixteen.
Connected
components are not computed in the high resolution image but only in the
low-resolution image. A low resolution image pixel with a count of one is
ignored when forming the parent image. The setting of low threshold is the sum
of the dynamic threshold procedure and the global threshold that adjusted by
the user. The high threshold is currently set at a constant either 4 higher
than the low threshold.
The early version of LOTS simply required a region to
have at least one pixel above the high threshold. Because the probability of
some noise pixels being above the high threshold increases with the number of
pixels in the regions, we changed the system to have the number of pixels required
to be above high threshold
increase to ceil (1/128 A), where A is the high resolution area of a region.
![]()
5. Parameterization for the experiments
We use median image of the
entire sequence as Primary Background Image and we initialize the Secondary Background
Image as Secondary Background Image= Primary Background Image.
In our work, without loss of generality, we presume the input at time t-1 was
closest to the primary background model Bp. For the thresholds we
use for low-threshold TL=0.1 and for high-threshold TH=0.4). The detection and
labelling step is performed on every frame after the initialization. In our
work in the experiments, we used ![]() and
and ![]() as proposed. In our
experiments, we used images of 320x240 pixels.
as proposed. In our
experiments, we used images of 320x240 pixels.
![]()
6. Results and discussion
This algorithm ([5],[7])
operates on grey scale images. It uses two background images and two per-pixel thresholds.
The two backgrounds model periodic changes. The per-pixel threshold image can
treat each pixel differently, allowing the detector to be robust to localized
noise in low-size image regions. The per-pixel threshold evolves according to a
pixel label provided by a Quasi Connected Components analysis (QCC).
Three test sequences were used for this study.
Each video sequences has 100 frames and 100 images were used to build the
background model. The resolution for each frame is 320 x 240 pixels and 24bit.
In figure 6 we test a video sequence with two moving objects (Twomen.avi) using
as TL=0.1 and TH=0.4 with satisfactory results. On the left of each
figure is illustrated the original image, in the middle the moving object and
on the right the background that we have used. In figure 6 we applied the LOTS
algorith using image sequences from the Oneman.avi and in figure 7 we applied
LOTS algorithm using images from a highway in

figure 5 Output Frames of Lots algorithm
Figure 5 shows the output
frames using Lots algorithm. The image in the left top row shows the current
frame image with the moving object, the right top the difference image and the
images in the bottom left and bottom right shows the two backgrounds, the
primary background and the secondary background.



Frame 2
Original
Moving Object
Primary Background



Frame 10
Original
Moving Object
Primary Background



Frame 20
Original
Moving Object
Primary Background



Frame 30 Original Moving Object Primary Background
figure
6 Results obtained when running the complete algorithm
on a video sequence
using
TL=0.1 and TH=0.4
(Twomen.avi)



Frame 5
Original Moving
Object Primary Background



Frame 15
Original Moving
Object Primary Background 


Frame 25
Original Moving
Object Primary Background



Frame
35 Original Moving Object Primary Background
figure
7 Results obtained when running the complete algorithm on a video sequence
using
TL=0.1 and TH=0.4 (Oneman.avi)



Frame
2 Original Moving Objects Primary Background



Frame
9 Original Moving Objects Primary Background



Frame
15 Original Moving Objects Primary Background



Frame
23 Original Moving Objects Primary Background
figure
8 Results obtained when running the complete algorithm on a video
sequence using
TL=0.1
and TH=0.4
(Norway-highway.avi)
![]()
7. Conclusions and future work
In this paper is presented a
method for background modelling. An object detection algorithm is implemented,
LOTS algorithm. No object detection algorithm is perfect, so is our method. In
short, the methods we presented for ‘smart’ visual surveillance show promising
results and can be both used as part of a real-time surveillance system or
utilized as a base for more advanced research such as activity analysis in
video. Using mixture models provides a flexible and powerful method for
background modelling.
Beside the various contributions in the present paper,
the complete framework for intelligent video analysis is still non perfect.
Many improvements could be introduced at several levels.
The generic framework for
intelligent video analysis as presented in paper still is uncompleted. We have
explored in our research some stages of this framework and not all the stages.
The exploration of the other stages (action recognition, semantic description,
personal identification and fusion of multiple cameras) makes the application
range wider. Thus, we can consider more advanced applications based on fusion
of multiple sensors as well as a recognition system for controlling high
security areas.
![]()
Bibliography
[1] Chris Stauffer and W. Eric
L. Grimson, (1999). Adaptive background
mixture models for real–time tracking. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition (CVPR), pages
II: 246–252.
[2] Richard A. Redner and
Homer F. Walker.(1984). Mixture
densities, maximum likelihood and the
[3] Andrea Prati, Ivana Mikic,
Mohan M. Trivedi, and Rita Cucchiara (2003). Detecting moving shadows: Formulation, algorithms and
evaluation. IEEE Transactions on Pattern Analysis and Machine
Intelligence, 25(7):918–923.
[4]
[5] T. Boult, R. Micheals, X. Gao, and M.
Eckmann, (2001). “Into the woods: Visual
surveillance of non-cooperative camouflaged targets in complex outdoor settings,”
in Proceedings of the IEEE, pp.
1382–1402.
[6] R. C. Gonzalez and R. E.
Woods, (2002). Digital Image Processing. Prentice Hall.
[7]
[8] C. Wren, A. Azabayejani, T. Darrell and A. Pentland: Pfinder, (1997). Real-time tracking of the human body IEEE Transactions on Pattern Analysis and
Machine Intelligence, pp.780-785.
[9] Jacinto Nascimento and
Jorge Marques, (2006). Performance evaluation
of object detection algorithms for video surveillance, Multimedia, IEEE Transactions on Volume 8, Issue 4,
Page(s):761 – 774.
[10] Qi Zang and Reinhard
Klette, (2003). Evaluation of an Adaptive
Composite Gaussian Model in Video Surveillance, pages 165-172, Computer
Science Department of the University of Auckland.
[11] D. M. Garvila, (1999). The Visual
Analysis of Human Movement: A Survey. In
Computer Vision and Image Understanding, Vol. 73, No. 1, pp. 82-98,
[12] Yigithan Dedeoglu, (2004). “Moving Object Detection, Tracking and Classification for smart video
surveillance”, Thesis.
[13] J.Heikkila and O.Silven. A
real time system for monitoring of cyclists and pedestrians. In proc. of
second IEEE Workshop on visual Surveillance, pages 74-81,
[14] K. Toyama, J. Krumm, B.
Brumitt and B. Meyers: Wallflower:
Principlesand practice of background
maintenance in: International
Conference on Computer Vision (1999) pp. 255-261.
[15] G. Halevy and D.Weinshall: Motion of disturbances: Detection and
tracking of multibody non-rigid motion Machine
Vision and Applications 11 (1999) 122-137, 1999.
![]()
©
Copyright-VIPAPHARM. All rights reserved

![]()
web hosting and internet marketing by Siteowners Ltd